MSSQL数据分区
1. 什么是分区
在sqlserver中,一般情况下所有的数据都是存储到一个文件上的(默认为.mdf文件),这样在数据非常多的时候效率肯定比较低。 而如果采用分区,数据就会按照我们指定的分区规则,存储到不同的文件,这样一来,一个非常的大文件就被分成了多个小文件,这样一来查询效率也会大大提升。
如果我们不做任何分区,也就是说,所有的数据都是存储在主数据文件(.mdf)中的。 如果进行了分区,那么我们就可以指定次要数据文件(.ndf)的数量,来分摊主数据文件的压力。除此之外,还有一个日志数据文件,也就是(.ldf)文件。
分区分为两种,一种是水平分区,另一种是垂直分区。
水平分区:对表的行进行分区。每个物理区域保存一定量的行数据,它们组合起来就是完整的表数据。进行水平分区,一定要指定某个属性列进行数据分割。比如:一年的订单表可以按照时间分四个区(这里就是按照时间进行数据分割的。)
垂直分区:对表的列进行分区。通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
2. 准备测试数据
在正式开始之前,我们需要先创建一些数据。创建了一个数据库(mydb),和一张订单表(order),并且往订单表中插入了1千万条测试数据。
create database mydb;
GO
use mydb
GO
create table order_detail
(
order_id bigint not null primary key nonclustered identity(1,1),
customer_id bigint not null,
goods_price decimal(10,2) not null,
create_time datetime not null,
);
GO
create clustered index create_time_clustered_index on order_detail(create_time)
GO
execute sp_addextendedproperty 'MS_Description', '订单编号', 'user', 'dbo', 'table', 'order_detail', 'column', 'order_id';
execute sp_addextendedproperty 'MS_Description', '用户id', 'user', 'dbo', 'table', 'order_detail', 'column', 'customer_id';
execute sp_addextendedproperty 'MS_Description', '商品数量', 'user', 'dbo', 'table', 'order_detail', 'column', 'goods_price';
execute sp_addextendedproperty 'MS_Description', '创建时间', 'user', 'dbo', 'table', 'order_detail', 'column', 'create_time';
GO
--插入1千万条数据,大概需要15分钟
declare @price_min Int=1 --测试数据最低价格
declare @price_max Int=1000000 --测试数据最高价格
declare @decimal Int=2 --价格保留小数点
declare @i int
set @i = 1
while @i < 10000000
begin
insert into order_detail(customer_id,goods_price,create_time)
values(
ABS(CHECKSUM(NEWID()))
,@price_min+round((@price_max-@price_min)*rand(),@decimal) --价格
,GETDATE()-(0.01*@i)/15); --插入时间,时间长度大概是19年
set @i = @i + 1;
end
3. 如何进行水平分区
在SQL Server中进行水平分区的过程不是一个简单的SQL命令就可以搞定的,它涉及到数据文件,文件组,分区函数,和分区方案。 下面笔者将会把这个过程划分成一个个的小步骤,并且为每个步骤都做了较为详细的解释。
3.1 创建文件组
这个步骤的作用就是指定数据分区后要存储的文件。这里有两个概念,一个是数据文件,另一个是文件组,一个文件组可以管理多个数据文件,我们在创建分区方案的时候就需要指定这些文件组。在创建分区完成后,分区表中的数据会按照我们指定的规则分散地存储到各个数据文件中。
既可以在创建数据库的时候创建文件组,也可以在数据库创建完成后再创建文件组。
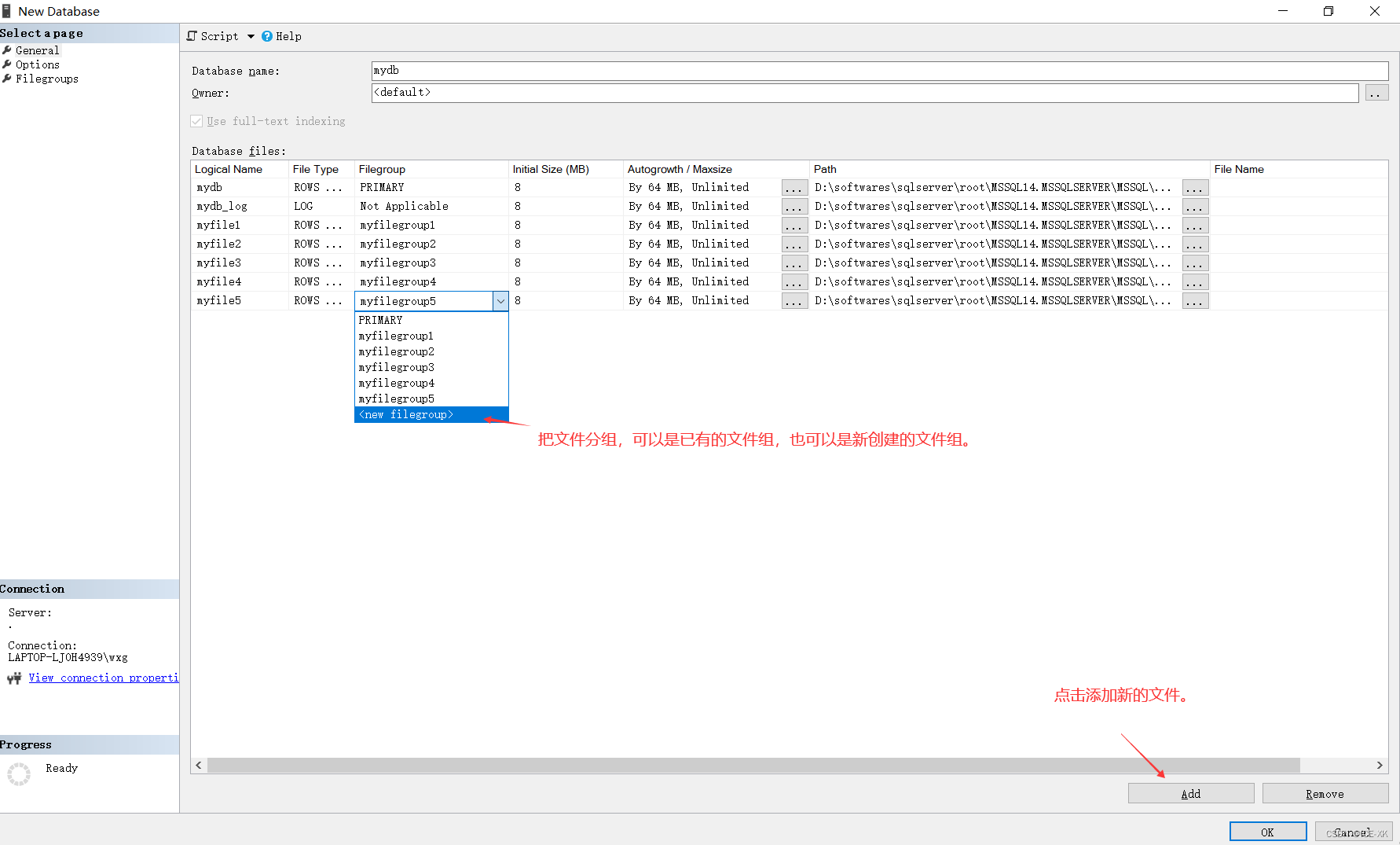
在创建完成数据库后,可以看到文件组可以被分为PRIMARY和你自定义的文件组两种。主数据文件(mydb)是属于PRIMARY文件组,并且不能被改变。myfile1,2,3,4,5是属于次要数据文件,次要数据文件的归组就比较随意,既可以是PRIMARY,也可以是你自定义的文件组。还有一个日志数据文件(mydb_log)不属于任何文件组。
创建完成后,打开你的数据存储目录,可以看到SQL Server为你创建了如下文件。

关于文件和文件组的更多信息,可以移步到 Microsoft Database Files and Filegroups。
上面展示了在创建数据库时候创建数据文件和文件组。其实也可以数据库创建完成后,再创建数据文件和文件组。
创建文件组
右键数据库 -> 属性(Properties) -> 文件组(Filegroups)
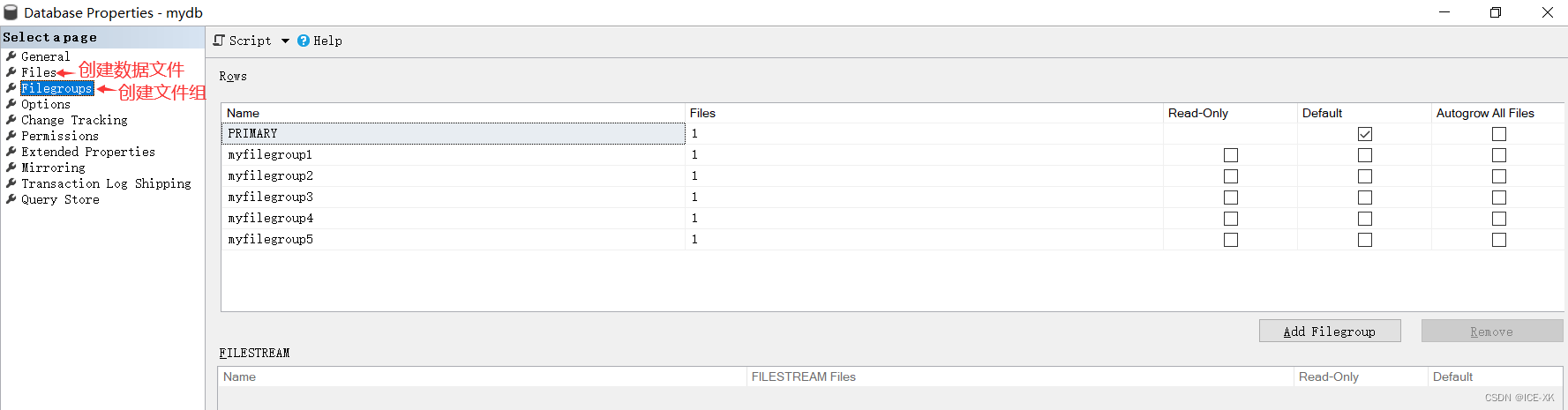
创建数据文件
右键数据库 -> 属性(Properties) -> 文件组(Files)
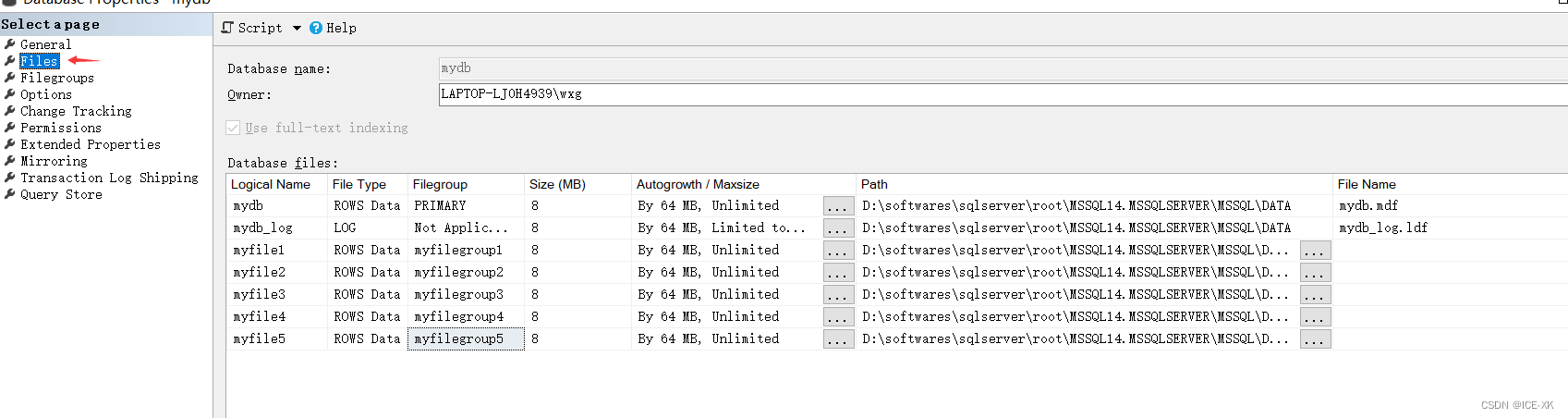
通过T-SQL创建数据文件和文件组
你也可以通过T-SQL脚本来创建数据文件和文件组
--创建数据库文件组
--alter database 数据库名称 add filegroup 文件组名称
alter database mydb add filegroup myfilegroup1
alter database mydb add filegroup myfilegroup2
alter database mydb add filegroup myfilegroup3
alter database mydb add filegroup myfilegroup4
alter database mydb add filegroup myfilegroup5
--创建数据文件
--alter database 数据库名称 add file
--(name=N'文件名称',filename=N'文件路径',size=文件初始,filegrowth=文件自动增量)
--to filegroup 文件组名称
alter database mydb add file
(name=N'myfile1',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile1.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup1
alter database mydb add file
(name=N'myfile2',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile2.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup2
alter database mydb add file
(name=N'myfile3',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile3.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup3
alter database mydb add file
(name=N'myfile4',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile4.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup4
alter database mydb add file
(name=N'myfile5',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile5.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup5
3.2 创建分区函数
上面已经创建了文件组,接下来就是创建分区函数,分区函数是数据库中的一个独立对象,它将表的行映射到一组分区,所以分区函数解决的是HOW的问题,即表如何分区的问题。
create partition function 分区函数名(<分区列类型>) as range [left/right] for values (每个分区的边界值,....)
上面的left代表左边界,right代表右边界。当 数据库引擎 按升序从左到右排序时,边界值是属于左侧还是右侧(默认为左侧)。换句话说,就是一个为小于等于,另一个为小于。
create partition function myPartitionFun(datetime) as range right for values ('2010-01-01 00:00:00','2017-01-01 00:00:00','2019-01-01 00:00:00','2020-01-01 00:00:00')
笔者数据库中所有数据的时间范围是2002到2020年。上面的时间间隔是呈现锥形分布的,之所以这么设计,这是因为订单表对当年发生的订单的操作是最频繁的,其次是1年前的订单(频繁),再就是2-3年的订单(操作比较频繁),再则就是3-10年的订单(操作偶尔发生),最后是10年前的订单(几乎不再操作订单),因此这个时间间隔是越来越大的。当然如果有对所有数据都有较为频繁的操作,可以分18个区(2002年到2020年),给每年都分区。
3.3 创建分区方案
分区方案定义了一个特定的分区函数将使用的物理存储结构(就是文件组),或者说是分区方案将分区函数生成的分区映射到我们定义的一组文件组。因此创建一个分区方案,需要分区函数和文件组名称。
create partition scheme <分区方案名称> as partition <分区函数名称> [all]to (文件组名称,....)
我们已经知道分区函数解决的就是HOW的问题, 而这个分区方案就是WHERE的问题,它把分区函数生成的分区映射映射到指定的一组文件组中。
create partition scheme myPartitionSchema as partition myPartitionFun to (myfilegroup1,myfilegroup2,myfilegroup3,myfilegroup4,myfilegroup5);
分区函数生成的分区数不能大于分区方案中指定的文件组数量。如果生成的分区数小于文件组的数量,那么多出的文件组,会被标记为下次使用的文件组。 myPartitionFun 指定了4临界值因此会生成5个分区, myPartitionSchema 恰好指定了5个文件组一一对应5个分区。
创建好分区方案后,可以在数据库 -> 存ⅲ⊿torage) -> 分区方案(Partition Schemas)中查看
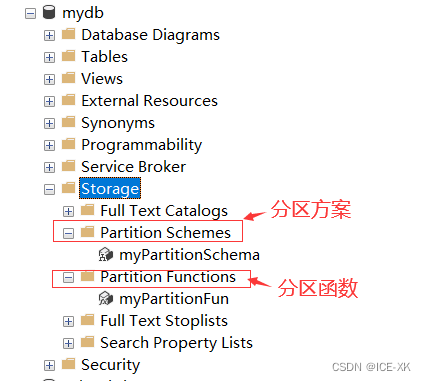
3.4 创建分区表
我们已经创建了分区方案了,接下来就是把分区方案应用到数据表上,这就是创建分区表。
create table <表名> (
<列定义>
)on<分区方案名>(分区列名)
例如:
create table MyOrder
(
id bigint not null identity(1,1),
order_num nvarchar(32) not null,
order_status int not null,
createtime datetime not null,
updatetime datetime not null,
order_desc nvarchar(500) null
)
on myPartitionSchema(id);
上面是创建了一个新表,并且指定了分区方案。由于在2.准备测试数据中已经创建了数据表,因此这里我们再不需要新建表,只需要将原来的表转化为分区表就可以了。
将普通表转化为分区表
分区表需要按照某一个字段把数据通过分区方案分到不同的文件中,而这个作为分区条件的字段必需要有聚集索引才可以。之前创建的表 order_detail 的聚集索引是在 create_time 上的,这里我们并不需要任何的修改。值得一提的是,分区方案实际上是和聚集索引关联的,而且如果你想要创建一个带分区方案的聚集索引(也就是给表分区),那么只有先删除之前的聚集索引,然后再创建一个带分区的聚集索引。这种带分区的聚集索引,也叫做分区索引。
--删除以前的聚集索引
DROP INDEX [create_time_clustered_index] ON [dbo].[order_detail] WITH ( ONLINE = OFF )
GO
--创建分区索引
CREATE CLUSTERED INDEX [create_time_clustered_index] ON [dbo].[order_detail]
(
create_time
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [myPartitionSchema]([create_time])
也可以通过向导把普通表转化为分区表
右键聚集索引 -> 属性(Properties) -> 存储(Storage)
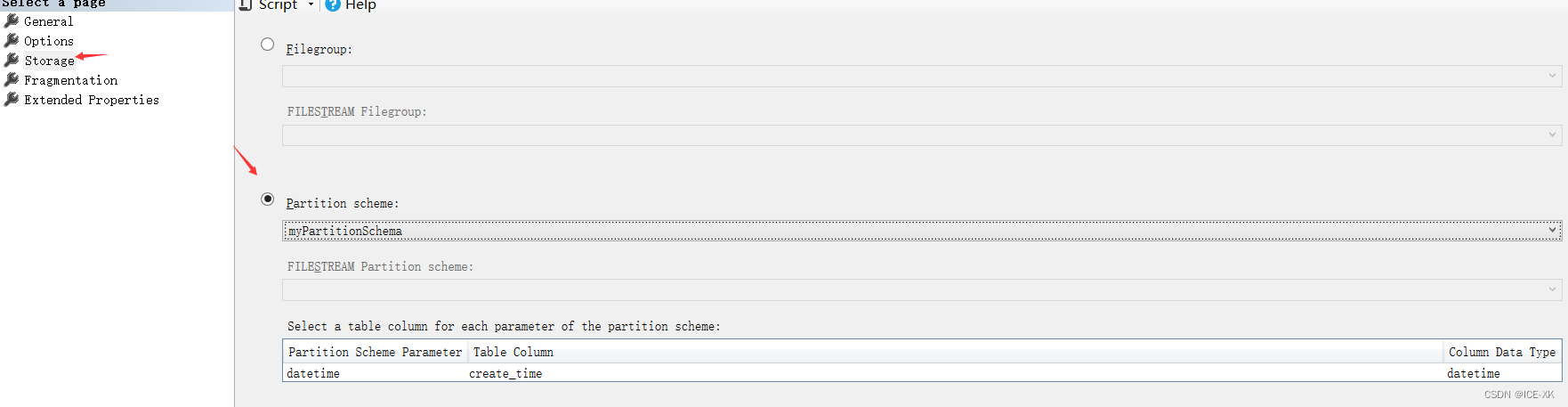
向导创建分区索引的过程也是显示吧旧聚集索引删除,然后再创建一个新的聚集索引并且指定分区方案。
3.5 使用分区向导创建分区表
上面介绍的几乎都是通过代码实现的,Microsoft SQL Server Management Studio 提供了更方便的图形化方式。
右键要分区的表 -> 存储(Storage)-> 创建分区(Create Partition)-> 下一步
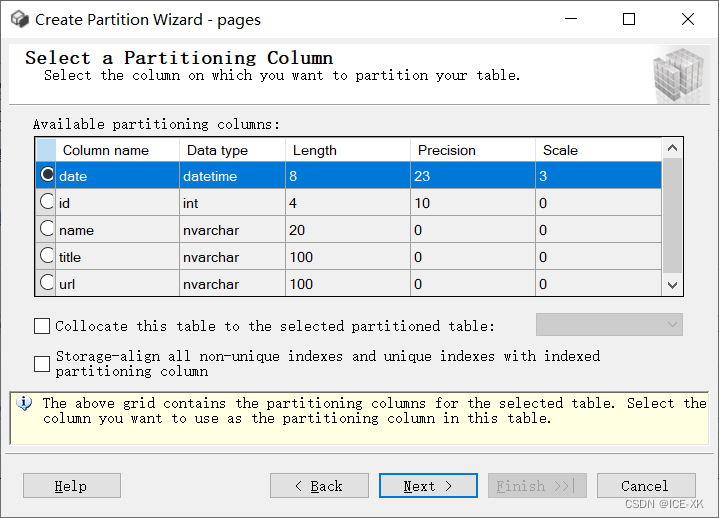
选择要分区的列
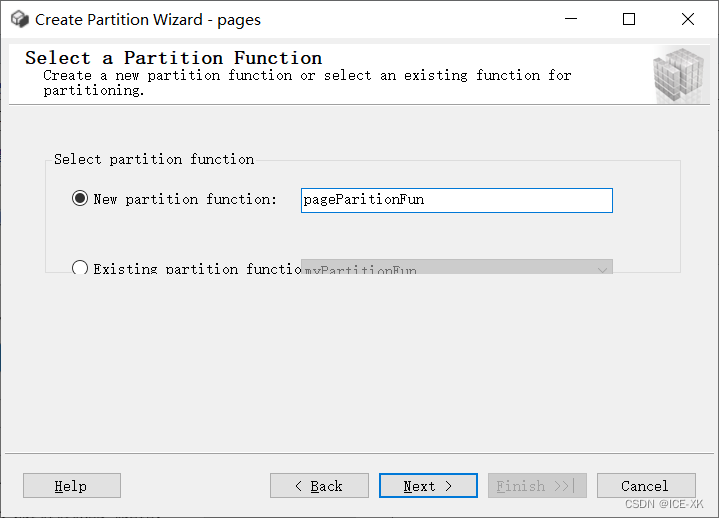
选择或创建分区函数
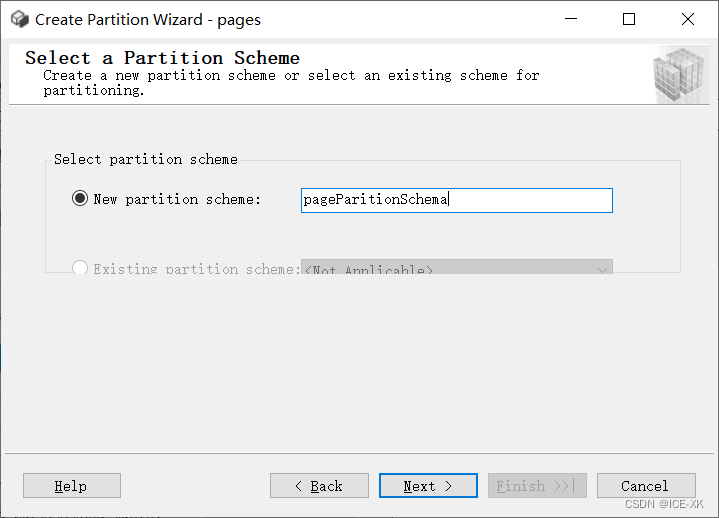
选择或创建分区方案
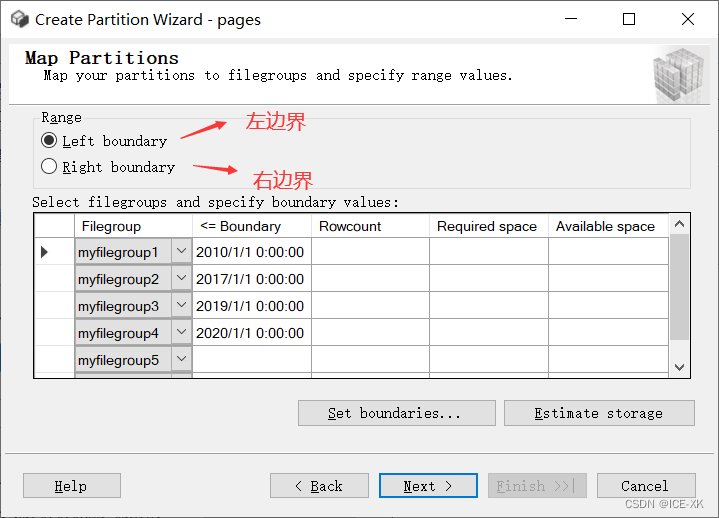
指定临界值,以及左边界或右边界。
3.6 秀一秀肌肉
到目前为止,分区表已经创建完成了,接下来就是秀一秀它的性能了。我准备了一张表 order_detail_non_partition ,数据和索引都和 order_detail 表一样,只是 order_detail_non_partition 只是没有分区。
--分区索引
select * from order_detail where create_time >= '2012-05-01 00:00:00' and create_time < '2019-06-01 00:00:00';
--无分区,聚集索引
select * from order_detail_non_partition where create_time >= '2012-05-01 00:00:00' and create_time < '2019-06-01 00:00:00';
笔者的打开了SQL SERVER Management Studio中的实时数据查询功能。

上面查询了2010年7月份到2020年9月份的所有数据,虽然查询所花费的时间都差不多,但是分区表在性能方面还是明显优于非分区表(I/O消耗,CPU消耗, 子树的大小,运算符的开销…)。
4. 关于表分区的常用管理
4.1 拆分分区
在分区函数中新增一个边界值。
--分区拆分
alter partition function myPartitionFun()
split range(N'2005-01-01T00:00:00.000')
如果分区函数已经关联了分区方案,那么分区数 不能大于分区方案中的文件组数。如果你的分区数和分区方案中的文件组数不符合要求,你可以先扩展分区方案中的文件组数,再扩展分区函数的临界值。
扩展分区方案中的文件组数
--新建立一个数据文件
alter database mydb add filegroup myfilegroup6
GO
--新建一个文件组
alter database mydb add file
(name=N'myfile6',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile6.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup6
GO
--添加文件组到分区方案
ALTER PARTITION SCHEME myPartitionSchema
NEXT USED myfilegroup6;
GO
4.2 合并分区
合并分区和拆分分区恰好相反,就是把两个分区合并为一个分区,可以通过删除分区函数中的临界值来完成。
--合并分区
alter partition function myPartitionFun()
merge range(N'2005-01-01T00:00:00.000')
4.3 查看指定数据所在的分区
当进行了表分区后,数据就会分散存储到不同的分区中。可以通过如下的命令,来查询数据到底存到那个分区中的:
--查询分区依据列为2020-08-28 14:34:02.890的数据在哪个分区上
select $partition.myPartitionFun(N'2020-08-28 14:34:02.890') --返回值是5,表示此值存在第5个分区
也可查询所有非空分区中存在的数据行数
--查看分区表中,每个非空分区存在的行数
select $partition.myPartitionFun(create_time) as partitionNum,count(*) as recordCount
from order_detail
group by $partition.myPartitionFun(create_time)
或是查询某个分区中的所有数据
---查看指定分区中的数据记录
select * from order_detail where $partition.myPartitionFun(create_time)=5
该文章在 2024/7/22 10:59:44 编辑过






 400 186 1886
400 186 1886


