DuckDB 是一款嵌入式OLAP数据库,专为高效分析型查询设计,被誉为“分析型SQLite”
admin
2025年5月30日 23:14
本文热度 6592
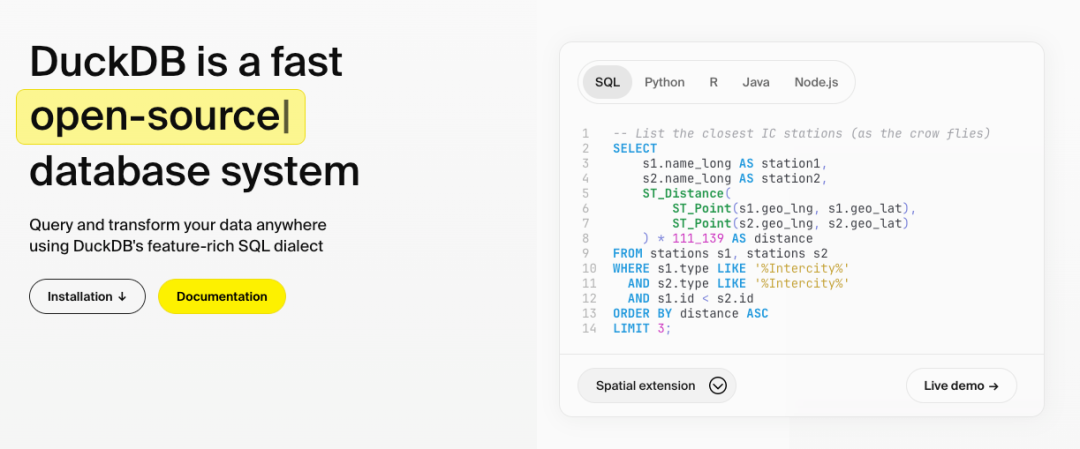
DuckDB 是一款 嵌入式OLAP数据库 ,专为高效分析型查询设计,被誉为“分析型SQLite”。它由荷兰CWI数据库团队开发,采用MIT开源协议,每月下载量超170万次,GitHub星标数达29.6k,增速与Snowflake相当,被DB-Engines预测为下一代主流分析引擎。
与传统行式数据库(如SQLite)不同,DuckDB采用 列式存储 和 向量化查询引擎 ,显著提升聚合计算、复杂过滤等分析任务的性能。它无需独立服务器,仅通过一个二进制文件嵌入应用,支持Python、R、Java等语言,5分钟即可上手。
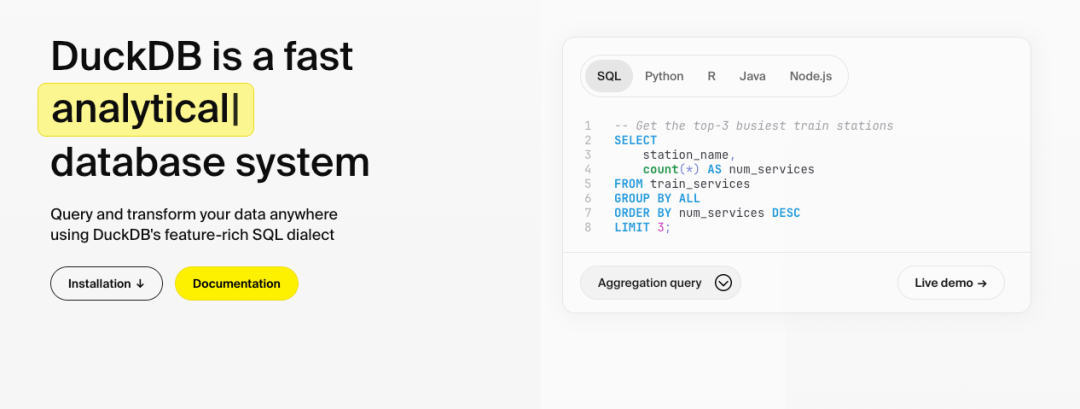
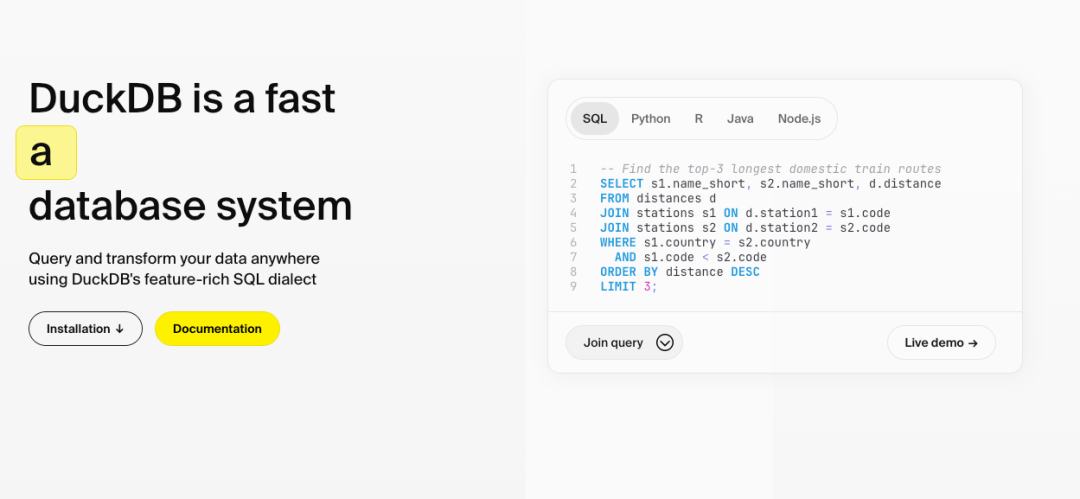
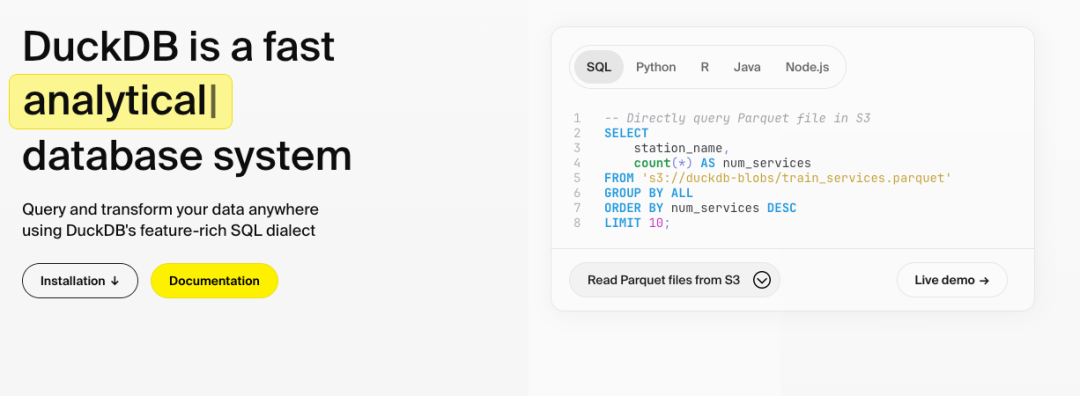
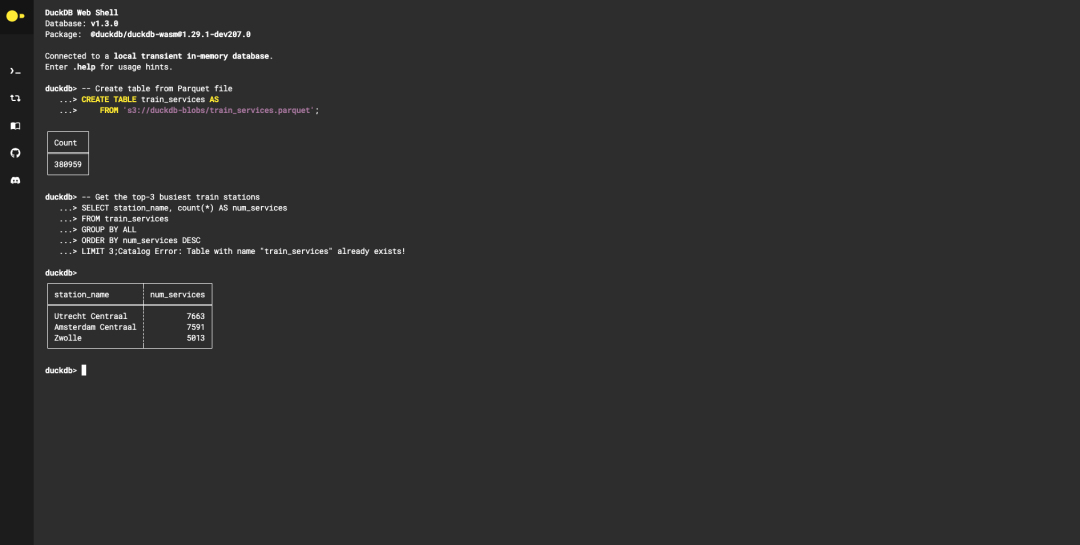
核心功能 一行命令安装: # macOS brew install duckdb # Python pip install duckdb 支持直接运行于浏览器(WebAssembly),无外部依赖。 Pandas零拷贝交互 :直接查询DataFrame,避免内存重复复制: import duckdb df = pd.read_csv( "data.csv" ) result = duckdb.sql( "SELECT * FROM df WHERE salary > 50000" ).df() 多格式直读 :直接查询CSV、JSON、Parquet文件,无需预加载: -- 查询远程Parquet文件 SELECT * FROM 's3://bucket/data.parquet' ; GROUP BY ALL :自动按所有非聚合字段分组,避免重复列名。 SELECT * EXCLUDE :排除指定字段,替代手动枚举: -- 排除email字段 SELECT * EXCLUDE (email) FROM customers; ASOF JOIN :高效连接“接近”的时间戳数据,替代复杂分桶逻辑。 超越内存限制的大数据处理 通过轻量压缩和智能溢出机制,即使数据量超过内存(如100GB),也能利用磁盘高效完成分析,成本仅为云方案的1/10。
混合云查询(MotherDuck) 结合本地与云端数据执行混合查询,无需修改SQL:
ATTACH 'md:' AS motherduck; -- 连接云服务 SELECT local_data.*, cloud_data.* FROM local_table local_data JOIN motherduck.main.cloud_table cloud_data USING ( id ); 🚀 行动建议 :
# 1. 安装Python库 pip install duckdb # 2. 试跑示例 duckdb.sql( "SELECT 'Hello, DuckDB!'" ) 用一行SQL开启你的高效分析之旅!
技术架构
💡 关键创新 :
向量化引擎 :以批处理单元(Vector)流转数据,减少函数调用开销; 字符串优化 :短字符串内联存储,长字符串保留4字节前缀加速比较; 无JIT依赖 :放弃LLVM编译,保障跨平台可移植性。 典型应用场景与案例 场景1:探索性数据分析(EDA) 问题 :Pandas处理10GB以上数据缓慢,内存不足。 方案 :用DuckDB替代聚合计算层:
# 从CSV加载1亿行数据 duckdb.sql( """ SELECT genre, AVG(rating) AS avg_rating FROM 'ratings.csv' GROUP BY ALL ORDER BY avg_rating DESC LIMIT 10; """ ).show() 效果 :速度提升5倍,内存占用降低60%。
场景2:数据湖ETL流水线 架构 :青铜层(原始数据)→ 白银层(清洗)→ 黄金层(聚合)。 DuckDB角色 :在白银层清洗JSON数据并序列化为Parquet:
# 从S3读取原始JSON,清洗后写回 duckdb.sql( """ COPY ( SELECT id, event_time, user_id FROM read_json('s3://bronze/events.json') WHERE user_id IS NOT NULL ) TO 's3://silver/events.parquet' (FORMAT PARQUET); """ ) 场景3:边缘设备实时分析 优势 :单文件部署(<50MB),适应硬件差异,防数据损坏。 案例 :工厂设备传感器数据实时聚合,延迟<100ms。
同类产品对比
语法事例
结论 替代Pandas/本地ClickHouse :DuckDB在10–100GB单机分析中性能领先; 补充云数仓 :MotherDuck实现混合查询,降低云端数据传输成本。 数据科学家 :替代Pandas处理中大型数据集,复用SQL技能; 嵌入式应用开发者 :需内置高性能分析功能的设备端应用; 数据工程师 :作为轻量级ETL引擎,桥接本地与云端数据流。 项目地址 https://github.com/duckdb/duckdb
阅读原文:原文链接






 400 186 1886
400 186 1886