

 400 186 1886
400 186 1886





前言
今天,我想和大家聊聊一个看似简单、却在实际项目中经常被忽略的话题:统计接口耗时。
有些小伙伴在工作中,可能经常遇到这样的场景:线上接口突然变慢,用户抱怨连连,你却一头雾水,不知道问题出在哪里。
或者,在性能优化时,你费尽心思优化了代码,却无法量化优化效果。
其实,这些问题都离不开一个基础技能——如何准确统计接口耗时。
今天,我就跟大家一起聊聊统计接口耗时的6种常见方法,希望对你会有所帮助。
最近准备面试的小伙伴,可以看一下这个宝藏网站(Java突击队):www.susan.net.cn,里面:面试八股文、场景设计题、面试真题、7个项目实战、工作内推什么都有。
为什么统计接口耗时如此重要?
在深入方法之前,我们先聊聊为什么接口耗时统计这么关键。
从架构师的角度看,这不仅仅是“记录一个时间”那么简单。
接口耗时直接反映了系统性能,它是:
- 性能优化的基石:没有耗时数据,优化就像盲人摸象,你根本不知道瓶颈在哪里。
- 监控告警的源头:通过耗时趋势,你可以提前发现系统异常,比如慢SQL、资源竞争等问题。
- 用户体验的晴雨表:接口响应时间直接影响用户满意度,尤其在高并发场景下,几毫秒的延迟都可能造成流失。
举个例子,有些小伙伴在工作中,可能直接用System.currentTimeMillis()在方法开始和结束处打日志,觉得这很简单。但如果你在多线程环境下这么做,可能会发现数据不准,因为系统时间可能被调整,或者日志输出本身影响性能。
这就是为什么我们需要更专业的方法。
好了,废话不多说,让我们开始今天的主菜。我将从最简单的原生Java方法,逐步深入到分布式系统中的高级工具,确保每种方法都讲透、讲懂。
方法一:System.currentTimeMillis()
这是最基础、最直接的方法,估计每个Java程序员都用过。
它的原理很简单:在方法开始时记录当前时间,在结束时再记录一次,然后计算差值。
为什么用这个方法?
对于一些简单的场景,比如测试某个方法块的执行时间,这种方法快速有效。
它不依赖任何第三方库,纯原生Java实现。
示例代码
public class SimpleTimeTracker {
public void processRequest() {
long startTime = System.currentTimeMillis(); // 记录开始时间
// 模拟业务处理:假设这里是一些核心逻辑
try {
Thread.sleep(100); // 模拟耗时操作,如数据库查询或外部API调用
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis(); // 记录结束时间
long duration = endTime - startTime; // 计算耗时
System.out.println("接口耗时: " + duration + "ms");
}
public static void main(String[] args) {
new SimpleTimeTracker().processRequest();
}
}
代码逻辑详解
System.currentTimeMillis()返回当前时间与1970年1月1日UTC时间的毫秒差。这是一个静态方法,调用成本很低。- 我们在方法入口处调用它,保存到
startTime变量。 - 在方法出口处再次调用,保存到
endTime变量。 - 耗时就是
endTime - startTime,单位是毫秒。 - 最后,我们打印出耗时,或者可以记录到日志系统中。
深度剖析
有些小伙伴在工作中可能觉得这方法太“土”,但它其实有几个隐藏问题:
- 精度问题:
System.currentTimeMillis()的精度是毫秒,对于短时间操作(比如几毫秒内的调用),可能无法准确测量。如果你需要更高精度,可以用System.nanoTime(),它返回纳秒级时间,但注意它不表示实际时间,只适合计算相对时间差。 - 系统时间影响:如果系统时间在过程中被调整(比如NTP同步),
currentTimeMillis可能回退或跳跃,导致计算出的耗时为负数或异常值。nanoTime不受此影响,因为它基于系统启动时间。 - 代码侵入性:你需要手动在每個方法中添加代码,如果接口众多,会显得臃肿,且容易遗漏。
为了更直观地理解这个过程,我画了一个流程图,展示了手动计时的基本流程:
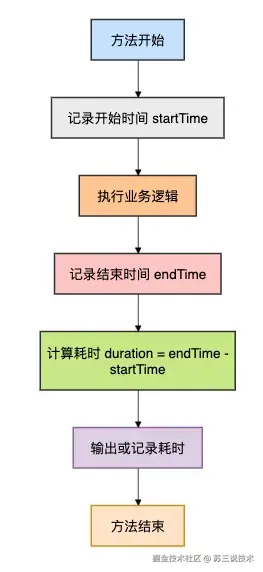
适用场景
- 快速调试或本地测试。
- 简单的单线程应用,不需要高精度。
- 作为学习其他方法的基础。
尽管这种方法有局限,但它让我们理解了核心思想:在关键点打点计时。
接下来,我们会看到如何用更优雅的方式实现类似功能。
方法二:System.nanoTime()
如果你对精度要求更高,比如需要统计微秒或纳秒级的操作,System.nanoTime()是更好的选择。
它专门用于测量时间间隔,而不是获取实际时间。
为什么用这个方法?
在高性能场景下,比如算法优化或低延迟交易系统,毫秒级精度可能不够。
nanoTime提供纳秒级精度,且不受系统时间调整影响。
示例代码
public class NanoTimeTracker {
public void processRequest() {
long startTime = System.nanoTime(); // 纳秒级开始时间
// 模拟业务处理
try {
Thread.sleep(100); // 注意:sleep单位是毫秒,实际业务可能是纳秒级操作
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.nanoTime(); // 纳秒级结束时间
long duration = (endTime - startTime) / 1_000_000; // 转换为毫秒
System.out.println("接口耗时: " + duration + "ms");
}
public static void main(String[] args) {
new NanoTimeTracker().processRequest();
}
}
代码逻辑详解
System.nanoTime()返回一个纳秒级的时间戳,但这个值只对计算相对时间差有意义。- 我们同样在开始和结束处调用,但计算出的
duration单位是纳秒。 - 为了方便阅读,我们通常转换为毫秒(除以1,000,000)。
- 注意:
Thread.sleep(100)是毫秒单位,这里只是模拟;实际业务可能是CPU密集型操作,适合用纳秒测量。
深度剖析
有些小伙伴在工作中可能混淆currentTimeMillis和nanoTime,关键区别在于:
- 用途不同:
currentTimeMillis用于获取实际时间(如日志时间戳),而nanoTime用于测量耗时。 - 精度和性能:
nanoTime通常精度更高,但调用成本可能略高(取决于JVM实现)。在现代JVM中,这个差异可以忽略。 - 溢出问题:
nanoTime的值可能溢出(虽然很少见),但因为是计算差值,只要时间间隔不超过292年(2^63纳秒),就不会有问题。
我建议:如果需要高精度测量,就用nanoTime;如果只是大概记录,用currentTimeMillis即可。
但这两种方法都有代码侵入性问题,接下来我们看看如何用AOP解决。
方法三:Spring AOP
Spring AOP(面向切面编程)是Java生态中解决横切关注点(如日志、耗时统计)的利器。
它允许你在不修改业务代码的情况下,动态添加功能。
为什么用这个方法?
作为架构师,我特别推崇AOP,因为它实现了“关注点分离”。
业务代码只关心核心逻辑,而耗时统计这种通用功能由切面处理。
这样代码更干净,也更易维护。
示例代码
首先,确保你的项目依赖了Spring AOP(例如在Spring Boot中,通常已包含)。
// 定义一个注解,用于标记需要统计耗时的方法
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public@interface TimeCost {
String value() default "";
}
// 编写切面类
@Aspect
@Component
publicclass TimeCostAspect {
privatestaticfinal Logger logger = LoggerFactory.getLogger(TimeCostAspect.class);
// 定义切点:标注了@TimeCost注解的方法
@Around("@annotation(timeCost)")
public Object around(ProceedingJoinPoint joinPoint, TimeCost timeCost) throws Throwable {
long startTime = System.currentTimeMillis();
Object result = null;
try {
result = joinPoint.proceed(); // 执行目标方法
} finally {
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
logger.info("方法 {} 耗时: {}ms", joinPoint.getSignature().getName(), duration);
}
return result;
}
}
// 在业务方法上使用注解
@Service
publicclass UserService {
@TimeCost("获取用户信息")
public User getUserById(Long id) {
// 模拟业务逻辑
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
returnnew User(id, "用户" + id);
}
}
代码逻辑详解
- 注解定义:
@TimeCost是一个自定义注解,用于标记需要统计耗时的方法。这样,我们可以在任何方法上添加它,而无需修改方法内部代码。 - 切面类:
TimeCostAspect使用@Aspect和@Component注解,表示这是一个Spring管理的切面。 @Around注解定义了环绕通知,它会在目标方法执行前后被调用。ProceedingJoinPoint参数代表被拦截的方法,proceed()方法用于执行原始方法。- 我们在
proceed()前后记录时间,并计算耗时。 - 使用日志记录耗时,避免控制台输出影响性能。
- 业务方法:在
getUserById方法上添加@TimeCost,即可自动统计耗时。
深度剖析
有些小伙伴在工作中可能对AOP的底层原理感兴趣。简单来说,Spring AOP基于动态代理实现:
- 如果目标类实现了接口,Spring使用JDK动态代理。
- 如果没实现接口,使用CGLIB字节码增强。
这带来了一个关键点:AOP只能拦截Spring管理的Bean方法,对于私有方法或非Bean对象无效。
此外,环绕通知的顺序也可能影响行为,如果有多个切面,可以用@Order注解控制顺序。
从性能角度看,AOP引入了一定的开销(代理调用),但在大多数应用中可忽略。它的最大优势是解耦,让业务代码保持纯净。
为了展示AOP的工作流程,我画了一个序列图:
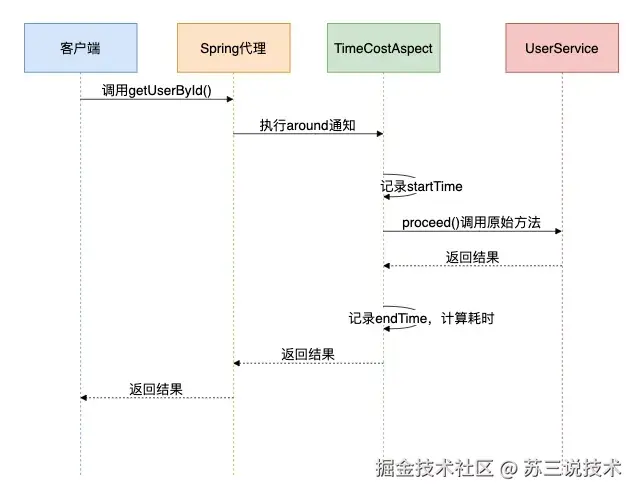
适用场景
- Spring项目,需要无侵入统计。
- 多个方法需要统一处理耗时逻辑。
- 团队协作时,避免业务代码被“污染”。
AOP虽然强大,但依赖于Spring框架。
如果你在用其他Web框架,或者需要更底层的控制,可以试试拦截器。
最近为了帮助大家找工作,专门建了一些工作内推群,各大城市都有,欢迎各位HR和找工作的小伙伴进群交流,群里目前已经收集了不少的工作内推岗位。加苏三的微信:li_su223,备注:掘金+所在城市,即可进群。
方法四:使用拦截器(Interceptor)
在Web应用中,拦截器是另一种常见的AOP实现方式,专门用于处理HTTP请求。
Spring MVC提供了HandlerInterceptor,可以拦截Controller方法的执行。
为什么用这个方法?
拦截器针对Web请求优化,它可以获取HTTP上下文信息(如请求参数、响应状态),非常适合统计接口级耗时。
相比AOP,它更轻量,且与Web层紧密集成。
示例代码
// 自定义拦截器
@Component
publicclass TimeCostInterceptor implements HandlerInterceptor {
privatestaticfinal Logger logger = LoggerFactory.getLogger(TimeCostInterceptor.class);
privatestaticfinal String START_TIME_ATTRIBUTE = "startTime";
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
long startTime = System.currentTimeMillis();
request.setAttribute(START_TIME_ATTRIBUTE, startTime); // 将开始时间存入请求属性
returntrue; // 继续执行链
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
long startTime = (Long) request.getAttribute(START_TIME_ATTRIBUTE);
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
logger.info("接口 {} 耗时: {}ms, 状态码: {}", request.getRequestURI(), duration, response.getStatus());
}
}
// 注册拦截器到Spring MVC
@Configuration
publicclass WebConfig implements WebMvcConfigurer {
@Autowired
private TimeCostInterceptor timeCostInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(timeCostInterceptor).addPathPatterns("/**"); // 拦截所有路径
}
}
代码逻辑详解
- 拦截器类:实现
HandlerInterceptor接口,重写preHandle和afterCompletion方法。 preHandle在Controller方法执行前调用,我们在这里记录开始时间,并存入请求属性(HttpServletRequest),以便后续使用。afterCompletion在请求完成后调用(包括视图渲染后),我们在这里取出开始时间,计算总耗时。- 注意:
afterCompletion即使请求抛出异常也会调用,这确保了耗时统计的完整性。
- 注册拦截器:通过
WebMvcConfigurer的addInterceptors方法,将拦截器注册到Spring MVC中,并指定拦截路径(这里是所有路径)。
深度剖析
有些小伙伴在工作中可能问:拦截器和AOP有什么区别?
- 粒度不同:拦截器针对Web请求,可以获取HTTP信息;AOP更通用,可以拦截任何Spring Bean方法。
- 执行时机:拦截器的
preHandle在Controller前,afterCompletion在视图渲染后;而AOP环绕通知只在方法执行前后。 - 性能:拦截器通常比AOP轻量,因为它专为Web优化。
一个常见陷阱是:拦截器统计的耗时包括视图渲染时间,而AOP只统计方法执行时间。
如果你只关心业务逻辑耗时,可能AOP更合适;如果需要全链路耗时(包括HTTP层),拦截器更好。
从架构角度,拦截器适合Web API的监控,而AOP适合业务方法监控。
它们可以结合使用,覆盖不同层次。
方法五:过滤器(Servlet Filter)
过滤器是Servlet规范的一部分,它在请求进入Servlet容器的最早阶段被调用,可以统计从接收到请求到返回响应的完整时间。
为什么用这个方法?
过滤器比拦截器更“底层”,它可以拦截所有请求(包括静态资源),且不依赖Spring框架。
如果你在用纯Servlet应用,或者需要统计整个请求生命周期,过滤器是理想选择。
示例代码
// 自定义过滤器
@Component
@Order(1) // 指定执行顺序,数字越小优先级越高
publicclass TimeCostFilter implements Filter {
privatestaticfinal Logger logger = LoggerFactory.getLogger(TimeCostFilter.class);
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
long startTime = System.currentTimeMillis();
try {
chain.doFilter(request, response); // 继续执行过滤器链
} finally {
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
HttpServletRequest httpRequest = (HttpServletRequest) request;
HttpServletResponse httpResponse = (HttpServletResponse) response;
logger.info("过滤器统计 - 接口 {} 耗时: {}ms, 状态码: {}", httpRequest.getRequestURI(), duration, httpResponse.getStatus());
}
}
}
// 注意:在Spring Boot中,@Component会自动注册过滤器;非Spring项目需在web.xml配置
代码逻辑详解
- 实现
Filter接口,重写doFilter方法。 - 在
doFilter开始时记录时间,然后调用chain.doFilter()将请求传递给下一个过滤器或Servlet。 - 在
finally块中计算耗时,确保即使抛出异常也能记录。 - 将
ServletRequest和ServletResponse转换为HTTP类型,以获取URI和状态码。 @Order(1)指定过滤器执行顺序,如果有多个过滤器,顺序很重要。
深度剖析
过滤器的关键特点是它在整个请求处理链的最外层。这意味着它统计的时间包括:
- 过滤器链执行时间。
- 拦截器执行时间。
- Controller方法执行时间。
- 视图渲染时间。
有些小伙伴在工作中可能发现过滤器耗时比拦截器长,原因就在于此。
此外,过滤器是Servlet标准,兼容任何Java Web容器(如Tomcat、Jetty),而拦截器是Spring特有。
从性能视角,过滤器非常高效,因为它直接嵌入Servlet容器。
但要注意,如果过滤器链过长,可能成为瓶颈。建议将耗时统计过滤器放在链首,以获取最准确的全链路时间。
为了对比过滤器、拦截器和AOP的范围,我画了一个层次图:
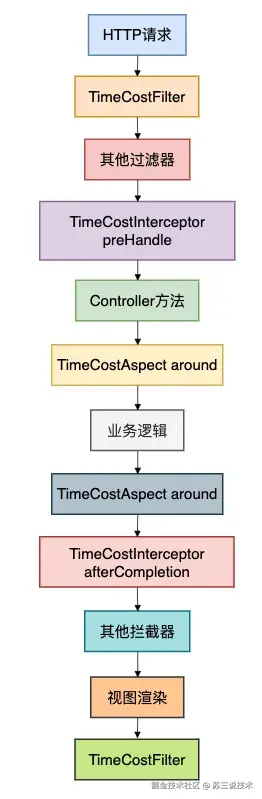
这个图清晰展示了三者的执行顺序和范围:过滤器最外层,拦截器在Spring MVC层,AOP在业务方法层。
方法六:Micrometer和APM工具
前面五种方法适合开发和测试环境,但在生产环境中,我们通常需要更强大的工具:比如Micrometer(指标收集库)或APM(应用性能管理)工具如SkyWalking。
这些工具提供分布式追踪、聚合统计和可视化功能。
为什么用这个方法?
我强烈推荐在生产环境使用专业工具。
因为它们:
- 低开销:针对生产环境优化,采集开销可控。
- 分布式支持:在微服务架构下,能追踪跨服务调用链。
- 丰富功能:提供百分位数、均值、峰值等统计,并与告警系统集成。
示例代码:使用Micrometer
Micrometer是一个指标门面库,可以对接多种监控系统(如Prometheus、Datadog)。这里以Spring Boot Actuator为例。
首先,添加依赖(在pom.xml):
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-core</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
然后,配置自动统计:
// 无需额外代码,Spring Boot自动集成Micrometer,通过Actuator端点暴露指标
// 在application.properties中启用Prometheus端点
management.endpoints.web.exposure.include=prometheus,metrics
手动定制统计:
@Service
publicclass OrderService {
privatefinal MeterRegistry meterRegistry;
privatefinal Timer orderProcessTimer;
public OrderService(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
this.orderProcessTimer = Timer.builder("order.process.time")
.description("订单处理耗时")
.register(meterRegistry);
}
public void processOrder(Order order) {
orderProcessTimer.record(() -> {
// 业务逻辑
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
代码逻辑详解
- 自动统计:Spring Boot Actuator自动为Web请求生成指标(如
http.server.requests),包括耗时、状态码等。 - 手动定制:我们注入
MeterRegistry,创建一个Timer指标,用于测量特定方法耗时。 Timer.record()方法接受一个Runnable或Callable,自动记录执行时间。- 指标数据可以通过
/actuator/prometheus端点暴露,供Prometheus采集。
深度剖析
有些小伙伴在工作中可能觉得Micrometer配置复杂,但它的优势在于标准化。
你只需写一次代码,就能对接多种监控后端。
对于更复杂的场景,APM工具如SkyWalking是更好的选择。
它们通过字节码增强(无需修改代码)自动采集数据,并提供全链路追踪。
例如,在SkyWalking中,你只需添加Java Agent,就能在UI上看到接口耗时拓扑图。
我建议:
- 中小项目:用Micrometer + Prometheus + Grafana,成本低,功能强大。
- 大型分布式系统:用APM工具如SkyWalking或Pinpoint,它们提供更细致的链路分析。
无论用哪种,核心思想是将耗时数据收集到中央系统,进行聚合和告警,而不是分散在日志中。
总结
经过以上6种方法的详细剖析,相信你对统计接口耗时有了更深入的理解。
下面是我的一些实用建议:
- 方法对比表:
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| System.currentTimeMillis() | 简单、无需依赖 | 精度低、代码侵入 | 本地测试、简单调试 |
| System.nanoTime() | 精度高 | 代码侵入、需转换单位 | 高性能测量、算法优化 |
| Spring AOP | 无侵入、解耦 | 仅Spring Bean、有代理开销 | 业务方法监控、Spring项目 |
| 拦截器 | Web优化、获取HTTP上下文 | 仅Web请求、包括视图时间 | Web API监控 |
| 过滤器 | 底层、全链路 | 包括所有过滤器时间 | 全请求生命周期统计 |
| Micrometer/APM | 生产级、分布式支持 | 配置复杂、需基础设施 | 生产环境、微服务架构 |
- 选择原则:
- 开发/测试环境:可以用AOP或拦截器,快速验证。
- 生产环境:务必使用Micrometer或APM工具,实现系统化监控。
- 精度要求:高精度用nanoTime,一般用毫秒即可。
- 代码维护:优先无侵入方案(AOP/拦截器),保持代码整洁。
- 最佳实践:
- 不要过度统计:只关注关键接口,避免性能开销。
- 结合日志和指标:耗时数据应同时记录到日志(用于调试)和指标系统(用于监控)。
- 设置基线告警:基于历史数据设置耗时阈值,自动触发告警。
有些小伙伴在工作中,可能一开始觉得这些方法很复杂,但一旦掌握,就能在性能优化和故障排查中游刃有余。
记住,统计接口耗时不是目的,而是手段,最终目标是为用户提供稳定、快速的服务。



